$Python$概况¶
$Python$语言简介¶
- $Python$ 是一种易于学习又功能强大的编程语言。
- 它提供了高效的高级数据结构($Numpy$,$Pandas$),还能简单有效地面向对象编程(封装,继承,多态;类、属性、方法)。
- Python 优雅的语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的理想语言。
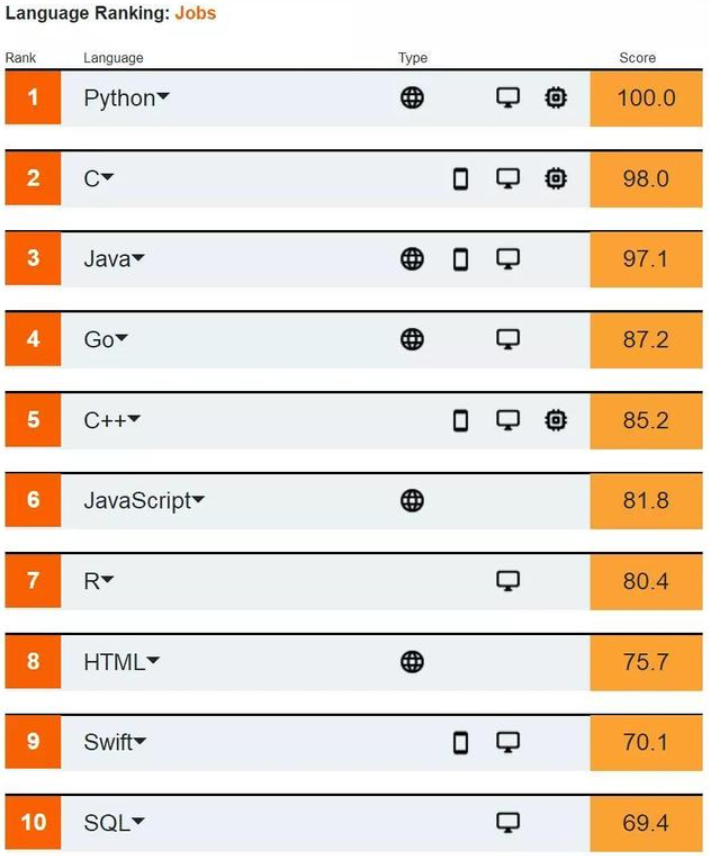
- $Python$是当下非常热门的一种编程语言。最近流行的编程语言排行榜是这样的:
$Python$ 的开发方向和应用场景¶
$Web$网络开发
- Python提供丰富的模块支持sockets编程,多线程编程,能方便快速地开发网络服务程序
- 支持最新的XML技术,支持json语言,数据库编程,Python的ORM框架,使得操作数据库非常方便
- Python的优秀Django、Tornado、Flask等web开发框架,众多开源插件支持可适用不同的web开发需求
- Django网站示例:爱与彼岸财经分析
自动化运维
- Python对操作系统服务的内置接口,使其成为编写可移植的维护操作系统的管理工具和部件的理想工具
- Python程序可以搜索文件和目录树,可以运行其他程序,可以使用进程和线程并行处理
网络爬虫
- 在文本处理方面,python提供的re模块能支持正则表达式
- Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架
图形处理
- 有PIL、Tkinter等图形库支持,能方便进行图形处理,多媒体应用
- Python的PyOpenGL模块封装了“OpenGL应用程序编程接口”,进行三维图像处理
- PyGame模块可用于编写游戏软件
当然$Python$最主要的应用是在于人工智能、大数据分析、机器人等领域
$Python$数据分析工具¶
$Matplotlib$
- 参见:Python系列:Matplotlib
- Matplotlib是基于Numpy的一套Python包,是Python的一个2D图形库,能够生成各种格式的图形(如折线图,散点图,直方图),界面可交互,图形库跨平台,既可在Python脚本中编码操作,也可在Jupyter Notebook中使用,以及其他平台都可以很方便的使用Matplotlib图形库,而且生成图形质量较高,甚至可以达到出版级别。
- 参见:Python系列:Matplotlib
$Numpy$
- 参见:Python系列:Numpy
- NumPy是使用Python进行科学计算的基础软件包,它包括功能强大的N维数组对象、精密广播功能函数、集成C/C+和Fortran代码的工具、强大的线性代数、傅立叶变换和随机数功能。
- NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。
- ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
- 参见:Python系列:Numpy
$Pandas$
- 参见:Python系列:Pandas DataFrame
- Pandas是一个开源的,BSD许可的库,为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
- Pandas库的亮点
- 一个快速、高效的$DataFrame$对象,用于数据操作和综合索引;
- 用于在内存数据结构和不同格式之间读写数据的工具:CSV和文本文件、Microsoft Excel、SQL数据库和快速HDF 5格式;
- 智能数据对齐和丢失数据的综合处理:在计算中获得基于标签的自动对齐,并轻松地将凌乱的数据操作为有序的形式;
- 数据集的灵活调整和旋转;
- 基于智能标签的切片、花式索引和大型数据集的子集;
- 可以从数据结构中插入和删除列,以实现大小可变;
- 通过在强大的引擎中聚合或转换数据,允许对数据集进行拆分应用组合操作;
- 数据集的高性能合并和连接;
- 层次轴索引提供了在低维数据结构中处理高维数据的直观方法;
- 时间序列-功能:日期范围生成和频率转换、移动窗口统计、移动窗口线性回归、日期转换和滞后。甚至在不丢失数据的情况下创建特定领域的时间偏移和加入时间序列;
- 对性能进行了高度优化,用Cython或C编写了关键代码路径。
- Python与Pandas在广泛的学术和商业领域中使用,包括金融,神经科学,经济学,统计学,广告,网络分析,等等。
- 参见:Python系列:Pandas DataFrame
$Scikit-Learn$
Scikit-Learn是基于Python机器学习的简单高效的数据挖掘和数据分析工具,基于BSD开源许可证。Scikit-Learn的安装需要Numpy,Scipy,Matplotlib等模块,主要功能分为六个部分:分类、回归、聚类、数据降维、模型选择、数据预处理。
$Scipy$
Scipy是一个用于数学、科学、工程领域的常用软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解决问题。
$Numpy$¶
矩阵乘法¶
import numpy as np
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
print('a is: \n' , a, '\n')
print('b is: \n' , b)
元素乘法¶
np.multiply(a,b)
矩阵乘法¶
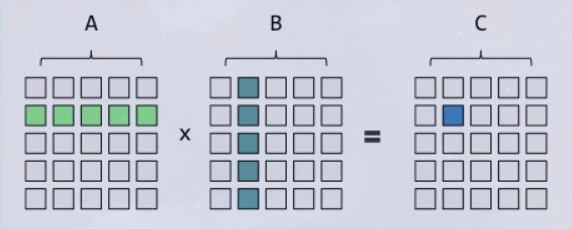
- 实际求解方程式中存在多项式矩阵
- 避免使用循环语句,提高运算效率
- 多项式矩阵示例:- 整形规划
#np.dot(a,b)
#np.matmul(a,b)
a.dot(b)
广播(Broadcasting)¶
- numpy在算术运算期间处理具有不同形状的数组
一个数组和一个标量值的广播¶
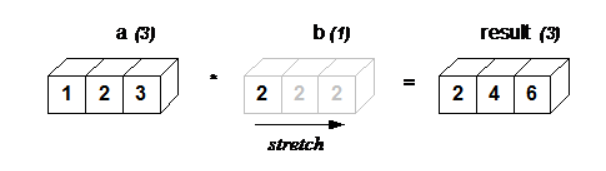
a = np.array([1.0, 2.0, 3.0])
b = 2.0
a * b
获取两个数组的外积¶
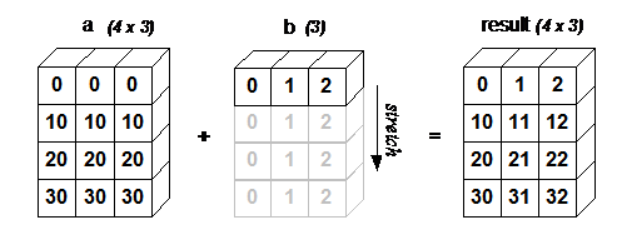
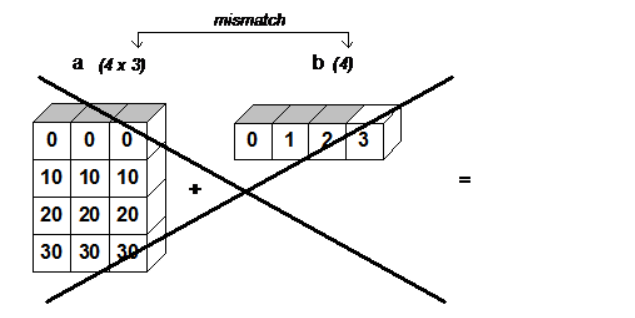
x = np.arange(4)
xx = x.reshape(4,1)
y = np.ones(5)
z = np.ones((4,5))
print(x,'\n')
print(xx,'\n')
# np.newaxis的功能:插入新维度
# 作用是将一维的数据转变成一个矩阵
print(x[:,np.newaxis],'\n')
print('y is: \n', y, '\n')
print('z is: \n', z, '\n')
w=[1,2,3,4,5]
print('w is: ', w,'\n')
tt1 = x[:,np.newaxis]*z
print('tt1 is: ', tt1)
tt2 = x[:,np.newaxis]*w
tt2
从输入到输出¶
读取文件内容¶
- Python 获取数据的方式:
- 在命令行运行 Python 脚本,用 sys.stdin 和 sys.stdout 以管道 (pipe) 方式传递数据
- 可以显式地用代码来读写文件获取数据
- 从网页获取数据,(爬虫,web spider)
- 使用 API (Application Programming Interface) 获取结构化格式(json)的数据
- 在科学计算领域,更多的是处理实验中所获得的数据,比如:传感器,采集卡,示波器,光谱仪等仪器采集的数据
with open('waveform.txt', 'r') as f:
t = f.readlines(2500)
t
# for l in f:
# print(l.replace('\n',''))
# for i, val in enumerate(f):
# print(i, ': ',val.replace('\n',''))
转化为数组¶
- np.genfromtxt()
- genfromtxt主要执行两个循环运算
- 第一个循环将文件的每一行转换成字符串序列
- 第二个循环将每个字符串序列转换为相应的数据类型。
import numpy as np
# skip_header跳过表头信息;delimiter区分横纵坐标
# autostrip 去除前后空格
data = np.genfromtxt('waveform.txt',delimiter=',',skip_header=19, autostrip=True)
data
对数组进行处理¶
import matplotlib.pyplot as plt
# 使用numpy二维数据的切片方式为x,y赋值
x=data[0:33,0]
y=data[0:33,1]
fig, axes = plt.subplots(figsize=(18,6))
axes.plot(x, y, 'r', linewidth=2)
axes.set_xlabel('Time(ps)')
axes.set_ylabel('Amplitude[a.u.]')
# fig.savefig("triangular.png", dpi=600)

结构化数组¶
- 结构化数组是ndarray,其数据类型是由一系列命名字段组织的简单数据类型组成
- 结构化数据类型旨在能够模仿C语言中的“结构”,并共享类似的内存布局,支持诸如子数组,嵌套数据类型和联合之类的专用功能。
- 希望操纵表格数据的用户(例如存储在csv文件中)可能会发现其他更适合的pydata项目,例如$xarray$,$pandas$ 或$DataArray$。这些为表格数据分析提供了高级接口,并且针对该用途进行了更好的优化。
- 示例:x 是一个长度为2的一维数组,其数据类型是一个包含三个字段的结构:
- 长度为10或更少的字符串,名为“name”
- 一个32位整数,名为“age”
- 一个32位的名为'weight'的float类型
x = np.array([('Rex', 9, 81.0), ('Fido', 3, 27.0)], dtype=[('name', 'U10'), ('age', 'i4'), ('weight', 'f4')])
print('x[1] is: ', x[1])
print('name is: ', x['name'])
print('dtype.names is: ', x.dtype.names)
print('dtype.fields is: ', x.dtype.fields)
print('age is: ', x['age'])
x
$Pandas$¶
- Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
- Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
- Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
数据结构¶
| 维数 | 名称 | 描述 |
|---|---|---|
| 1 | Series | 带标签的一维同构数组 |
| 2 | DataFrame | 带标签的,大小可变的,二维异构表格 |
与 $SQL$ 的比较¶
$limit$¶
import pandas as pd
tips = pd.read_csv('sku_list.csv')
# postgresql
# select * from sku_list limit 5
tips.head()
$select$¶
# postgresql
# select skuname, skuprice, storename from sku_list limit 5
tips[['skuname', 'skuprice', 'storename']].head(5)
$where$¶
# postgresql
# select * from sku_list where storename = '霖蒙小店' and skuprice>2000 limit 5
tips[(tips['storename'] == '霖蒙小店') & (tips['skuprice']>2000)].head(5)
$where、select、limit$组合¶
# 组合
tips[(tips['storename'] == '霖蒙小店') & (tips['skuprice']>2000)][['skuname', 'skuprice', 'storename']].head(5)
$group$ $by$
# SELECT storename, count(*) FROM sku_list GROUP BY storename;
tips.groupby('storename').size()
# count()将函数应用于每个列,返回每个列中的记录数。not null
tips.groupby('storename').count()
tips.groupby('storename')['skuprice'].count()
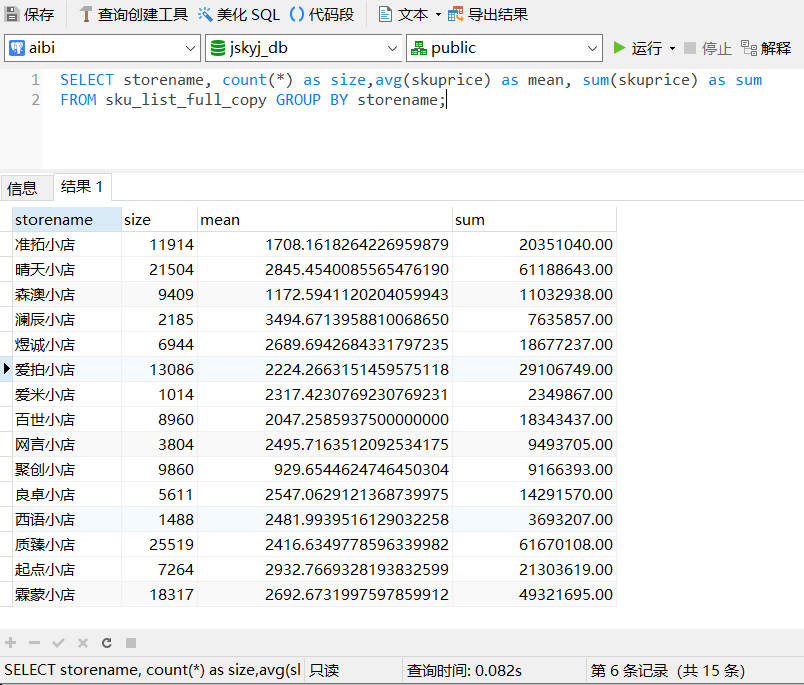
# SELECT storename, avg(skuprice) as mean, sum(skuprice) as sum FROM sku_list GROUP BY storename;
tips.groupby('storename').agg({'skuprice': [np.size, np.mean, np.sum]})
$join\ (inner\ join,left\ join,right\ join)$¶
# SELECT * FROM sku_list as df1 left join sku_list as df2 ON df1.storename = df2.storename;
pd.merge(tips, tips, on='storename', how='left')
$union$¶
# SELECT skuname, skuprice, storename FROM sku_list df1 UNION ALL SELECT skuname, skuprice, storename FROM sku_list df2;
d1 = tips[(tips['storename'] == '霖蒙小店') & (tips['skuprice']>2000)][['skuname', 'skuprice', 'storename']].head(5)
d2 = tips[(tips['storename'] == '晴天小店') & (tips['skuprice']>2000)][['skuname', 'skuprice', 'storename']].head(5)
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
df1
df2
# 合并
pd.concat([df1, df2])
数据准备¶
数据类型¶
数字 Number¶
整数¶
- 可处理任意大小的整数,包括负整数
n1=10
n2=n1
print('n1 is: ',n1)
print('n2 is: ',n2)
n3=n4=n5=8
print('n3 is: ',n3)
print('n4 is: ',n4)
print('n5 is: ',n5)
n6,n7=5,9
print('n6 is: ',n6)
print('n7 is: ',n7)
浮点数¶
- 浮点数由整数部分和小数部分组成
- 浮点数运算可能会有四舍五入的误差
f1=1.1
f2=2.2
print(f1+f2)
# 保留两位小数
f3 = round(f1+f2, 2)
print(f3)
f12= f1+f2
# 保留两位小数(第二种方法)
f4 = '%.2f' % f12
print(f4)
数字类型转换¶
#转化为整数
ti1 = int(1.035)
print(ti1)
ti2 = int('-555')
print(ti2)
ti3=ti1+ti2
print(ti3)
tf1 = float(5)
print(tf1)
tf2 = tf1+ti2
print(tf2)
数学函数¶
# 取绝对值
print(abs(-11))
# 大于小于等于
print(6<9)
print(6>9)
# 布尔值对比
print((6<9)-(6>9))
print((6>9)-(6<9))
# 最大和最小
print(max(1,2,3,4,5))
print(min(1,2,3,4,5))
# x的y次方
print(pow(3,3))
# 保留y位小数点
print(round(1.55555555,3))
import math
# 向上取整
print(math.ceil(18.3))
print(math.ceil(18.7))
#向下取整
print(math.floor(18.3))
print(math.floor(18.7))
# 返回整数部分和小数部分(返回一个元组)
print(math.modf(18.7))
# 返回平方根
print(math.sqrt(25))
随机数函数¶
import random
for i in range(10):
print(random.choice([1,2,'abc',3,4,5]))
# 随机生成1-100之间的整数
import random
for i in range(10):
print(random.choice(range(100))+1)
# 随机生成0到1之间的浮点数
import random
for i in range(10):
print(random.random())
# 随机生成0到9之间的整数
import random
for i in range(10):
print(random.randint(0,9))
# 随机生成x到y之间的浮点数
import random
for i in range(10):
print(random.uniform(8,9))
字符串 string¶
字符串创建与切片¶
str1= 'hello python'
print(str1)
print(str1[3:8])
print(str1[6:])
print(str1[:5])
字符串连接¶
str2='aaa'
str3='bbb'
str4=str2+str3
str4
str5="".join([str2,str3])
str5
字符串格式化¶
s3='{3}{2}'.format('12345','aaa','bbb','ccc')
print(type(s3))
s3
a = "%(name)s: %(age)d "%{'name':'Jasper','age':20}
a
s1 = '%s %d'%('bbb',111)
print(type(s1))
s1
print("博客:{name}, 地址: {url}".format(name="爱与彼岸", url="https://www.jasper.wang"))
字符串函数¶
str= 'abcabcabc'
str.count('a', 0,len(str))
str1 = "hello jasper"
str2 = "e"
print (str1.find(str2))
info = 'abca'
print(info.find('a')) # 从下标0开始,查找在字符串里第一个出现的子串,返回结果:0
print(info.find('a', 1)) # 从下标1开始,查找在字符串里第一个出现的子串:返回结果:3
print(info.find('3')) # 查找不到返回-1
str="Hello World"
print(str.index("Hello")) # 返回值:0
print(str.index("o")) # 返回值:4
print(str.index("W")) # 返回值:6
# print(str.index("R")) # 返回值:报错信息 ,因为R并不包含其中。 所以建议慎用,如果值不存在程序报错就完蛋了。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度width的新字符串 |
| string.count(str,beg=0,end=len(string)) | 返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数 |
| string.decode(encoding='UTF-8',errors='strict') | 以encoding指定的编码格式解码string,如果出错默认报一个ValueError的异常,除非errors指定的是'ignore'或者'replace' |
| string.encode(encoding='UTF-8',errors='strict') | 以encoding指定的编码格式编码string,如果出错默认报一个ValueError的异常,除非errors指定的是'ignore'或者'replace' |
| string.endswith(obj,beg=0,end=len(string)) | 检查字符串是否以obj结束,如果beg或者end指定则检查指定的范围内是否以obj结束,如果是,返回True,否则返回False. |
| string.expandtabs(tabsize=8) | 把字符串string中的tab符号转为空格,tab符号默认的空格数是8。 |
| string.find(str,beg=0,end=len(string)) | 检测str是否包含在string中,如果beg和end指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str,beg=0,end=len(string)) | 跟find()方法一样,只不过如果str不在string中会报一个异常. |
| string.isalnum() | 如果string至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False |
| string.isalpha() | 如果string至少有一个字符并且所有字符都是字母则返回True,否则返回False |
| string.isdecimal() | 如果string只包含十进制数字则返回True否则返回False. |
| string.isdigit() | 如果string只包含数字则返回True否则返回False. |
| string.islower() | 如果string中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回True,否则返回False |
| string.isnumeric() | 如果string中只包含数字字符,则返回True,否则返回False |
| string.isspace() | 如果string中只包含空格,则返回True,否则返回False. |
| string.istitle() | 如果string是标题化的(见title())则返回True,否则返回False |
| string.isupper() | 如果string中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True,否则返回False |
| string.join(seq) | 以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度width的新字符串 |
| string.lower() | 转换string中所有大写字符为小写. |
| string.lstrip() | 截掉string左边的空格 |
| string.maketrans(intab,outtab]) | maketrans()方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像find()和split()的结合体,从str出现的第一个位置起,把字符串string分成一个3元素的元组(string_pre_str,str,string_post_str),如果string中不包含str则string_pre_str==string. |
| string.replace(str1,str2, num=string.count(str1)) | 把string中的str1替换成str2,如果num指定,则替换不超过num次. |
| string.rfind(str,beg=0,end=len(string)) | 类似于find()函数,不过是从右边开始查找. |
| string.rindex(str,beg=0,end=len(string)) | 类似于index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度width的新字符串 |
| string.rpartition(str) | 类似于partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除string字符串末尾的空格. |
| string.split(str="",num=string.count(str)) | 以str为分隔符切片string,如果num有指定值,则仅分隔num+个子字符串 |
| string.splitlines([keepends]) | 按照行('\r','\r\n',\n')分隔,返回一个包含各行作为元素的列表,如果参数keepends为False,不包含换行符,如果为True,则保留换行符。 |
| string.startswith(obj,beg=0,end=len(string)) | 检查字符串是否是以obj开头,是则返回True,否则返回False。如果beg和end指定值,则在指定范围内检查. |
| string.strip([obj]) | 在string上执行lstrip()和rstrip() |
| string.swapcase() | 翻转string中的大小写 |
| string.title() | 返回"标题化"的string,就是说所有单词都是以大写开始,其余字母均为小写(见istitle()) |
| string.translate(str,del="") | 根据str给出的表(包含256个字符)转换string的字符,要过滤掉的字符放到del参数中 |
| string.upper() | 转换string中的小写字母为大写 |
| string.zfill(width) | 返回长度为width的字符串,原字符串string右对齐,前面填充0 |
字符串转义¶
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \000 | 空 |
| \n | 换行 |
| \r | 回车 |
布尔值 Bookean¶
- 一个布尔值只有True、False两种值
- 条件语句和循环语句都使用布尔表达式作为条件
- 布尔操作符: and,or 和 not
- Python中布尔操作符的优先级,从高分到低分依次是not、 and最低是or
布尔表达式¶
- 壁球比赛计分例子
- a 和 b 代表两个壁球选手的分数
- 规则1:只要一个选手达到了15分,本场比赛就结束; 如果一方打了七分而另一方一分未得时,比赛也会结束
- 规则2:需要一个团队赢得至少两分才算赢,即其中一个队已经达到了15分,且分数差异至少为2时比赛结束
a=15
b=11
# 规则1
if (a==15 or b==15) or (a==7 and b==0) or (a==0 and b==7):
print('比赛结束')
# 规则2
if (a==15 and (a-b)>=2) or (b==15 and (b-a)>=2) or (a==7 and b==0) or (a==0 and b==7):
print('比赛结束')
布尔代数¶
bool(0)
bool('')
bool([])
bool({})
bool(None)
True\False|and\or组合¶
bool(a or True)
bool(a or False)
bool(a and True)
bool(a and False)
空值 None¶
- 在Python中,尤其是数组当中,对于一些异常值往往需要进行特殊处理。
- 为了防止异常值与正常数据混淆,影响最终计算结果,常用的方法是将异常值置零或者置空。
- 空值是一个特殊的常量 None(N 必须大写)。
- 和 False 不同,它不表示 0,也不表示空字符串,而表示没有值,也就是空值。
bool(None==0)
bool(None==False)
bool(None==True)
None is 0
None is ''
None==None
type(None)
i = 1
i = None # int 型数据置空
s = "string"
s = None # 字符串型数据置空
l = [1,2,3,4]
l[2] = None # 列表中元素置空
print(i,'\n',s,'\n', l,'\n')
列表 List¶
- 特征:
- 列表中的每个元素都可变的,意味着可以对每个元素进行修改和删除;
- 列表是有序的,每个元素的位置是确定的,可以用索引去访问每个元素;
- 列表中的元素可以是Python中的任何对象;
- 可以为任意对象就意味着元素可以是字符串、整数、元组、也可以是list等Python中的对象。
list 函数¶
l = list("Hello world")
l
# 列表遍历
for i in l:
print(i)
# 包含索引的列表遍历
for key, val in enumerate(l):
print(key,': ', val)
list 操作¶
# 直接创建列表
mylist = ['Google', 'Yahoo', 'Baidu']
mylist
# 对列表中的指定位置变更数据
mylist[1] = 'Microsoft'
mylist
# 在列表后面追加元素
mylist.append('Alibaba')
mylist
# 在指定位置插入元素
mylist.insert(1, 'Tencent')
mylist
# 删除尾部元素
templist = mylist.copy()
print(templist)
# 返回被删除元素
t = templist.pop()
print(templist)
print(t)
# 删除指定位置的元素
templist = mylist.copy()
print(templist)
t2 = templist.pop(1) # 删除索引为1的元素,并返回删除的元素
t2
# 删除列表中的Microsoft
templist = mylist.copy()
print(templist)
templist.remove('Microsoft')
templist
# 删除列表中索引位置1到位置3(不含)的数据
templist = mylist.copy()
print(templist)
del templist[1:3]
templist
# 替换元素
templist = mylist.copy()
print(templist)
templist[0] = 'Baidu'
# 集合的数据类型可以不同,也可以是集合
templist[1] = ['python', 'java', 'php']
templist
# 列表排序
templist = mylist.copy()
print(templist)
templist.sort()
templist
# 获取列表长度
len(mylist)
# 获取列表指定位置的数据
print(mylist)
print('mylist[1] is: ', mylist[1])
print('mylist[2:] is: ',mylist[2:])
print('mylist[1:5] is: ',mylist[1:5])
print('mylist[:3] is: ',mylist[:3])
# 用循环来创建列表
a = [1,2,3,4,5,6]
#在a的数据基础上每个数据乘以10,再生成一个列表b,
b = [i*10 for i in a]
print(a)
print(b)
# 过滤列表中的内容放入新的列表中
#生成一个从1到20的列表
a = [x for x in range(1,20)]
print(a)
#把a中所有偶数生成一个新的列表b
b = [m for m in a if m % 2 == 0]
print(b)
# 嵌套式生成列表
#生成一个列表a
a = [i for i in range(1,4)]
print(a)
#生成一个列表b
b = [i for i in range(100,400) if i % 100 == 0]
print(b)
# 嵌套式
c = [m*n for m in a for n in b]
print(c)
# 去重且保持顺序不变
print(c)
c_sort = []
[c_sort.append(i) for i in c if not i in c_sort]
c_sort
元组 Tuple¶
- 元组Tuple,用法与List类似
- 但Tuple一经初始化,就不能修改,没有List中的append(), insert(), pop()等修改的方法,只能对元素进行查询
- 元组的意义何在呢?
- 因为tuple不可变,所以代码更安全。
- 如果可能,能用tuple代替list就尽量用tuple并且需要注意元组中元素的可变性!
a = (1,2,3,4)
print(a)
print(type(a))
# 证明了元组不可修改
# TypeError: 'tuple' object does not support item assignment
a[1]=5
a[1]
b = ('a','b',['A','B'])
b
# 元组中的列表的内容,是可以修改的
b[2][0] = 'X'
b[2][1] = 'Y'
b
# 元组中的列表的内容,是可以修改的
print(type(b[2]))
# 空的tuple可以记为(),若只有一个元素的tuple记为(1,)
tb = ()
print(tb)
t = (1,)
t
字典 Dict¶
- 使用键(key)-值(value)对的形式存储
- dict的显著特征:
- 字典中的数据必须以键值对的形式出现,即 k,v:
- key:必须是可哈希的值,比如intmstring, float, tuple,但是,list, set, dict不行
- value:任何值
- 键不可重复,值可重复
- 键若重复字典中只会记该键对应的最后一个值
- 字典中键(key)是不可变的,不能进行修改;而值(value)是可以修改的,可以是任何对象。
- 在dict中根据key来计算value的存储位置
- 字典中的数据必须以键值对的形式出现,即 k,v:
字典创建¶
# 创建空字典1
d = {}
d
# 创建空字典2
d = dict()
d
# 直接赋值方式
d = {"one":1,"two":2,"three":3,"four":4}
d
# 常规字典生成式
d2 = {k:v for k,v in d.items()}
d2
# 加限制条件的字典生成方式
d3 = {k:v for k,v in d.items() if v % 2 ==0}
d3
字典操作¶
# 访问字典中的数据
d = {"one":1,"two":2,"three":3,"four":4}
d["one"]
# 变更字典里面的数据
d["one"] = "11111"
d
# 删除一个数据,使用del
del d2["one"]
d2
# 判断 键 是否存在于 字典 中
d.__contains__('ones')
if d.__contains__('one'):
print(d['one'])
# 判断 键 是否存在于 字典 中
if "two" in d2:
print("key")
# 字典成员检测
dm = {"one":1,"two":'2',"three":3,"four":4}
dm.keys()
dm.values()
# 利用 keys() 、values()、index() 函数
# 查找 value 对应的 key 值
list (dm.keys())[list (dm.values()).index('2')]
[list (dm.values()).index('2')]
[k for k, v in dm.items() if v == '2']
for循环访问字典¶
for k in d:
print(k,': ',d[k])
for k in d.keys():
print(k,': ',d[k])
for v in d.values():
print(v)
for k,v in d.items():
print(k,'--->',v)
字典相关函数¶
dfunc = {"5":1,"2":2,"1":3,"9":4}
print(dfunc)
print(max(dfunc.keys()))
print(min(dfunc))
print(len(dfunc))
# dict() 函数的使用方法
dict0 = dict() # 传一个空字典
print('dict0:', dict0)
dict1 = dict({'three': 3, 'four': 4}) # 传一个字典
print('dict1:', dict1)
dict2 = dict(five=5, six=6) # 传关键字
print('dict2:', dict2)
dict3 = dict([('seven', 7), ('eight', 8)]) # 传一个包含一个或多个元祖的列表
print('dict3:', dict3)
dict5 = dict(zip(['eleven', 'twelve'], [11, 12])) # 传一个zip()函数
print('dict5:', dict5)
#返回字典的字符串格式
ds = {"one":1,"two":2,"three":3,"four":4}
print(str(ds))
# items:返回字典的键值对组成的元组格式
di = {"one":1,"two":2,"three":3,"four":4}
i = di.items()
print(type(i))
print(i)
for j in di.items():
print(j[0],': ',j[1])
di.clear()
print(di)
# get:根据制定键返回相应的值,好处是可以设置默认值
# 如果有key,返回value,如果无,返回默认值
dg = {"one":1,"two":2,"three":3,"four":4}
print(dg.get("one333"))
#get默认值是None,可以设置
print(dg.get("one",100))
print(dg.get("one222",100))
# fromkeys:使用指定的序列作为键,使用一个值作为字典的所有的键的值
p = ["one","two","three","four",]
#注意fromkeys两个参数的类型
#注意fromkeys的调用主体
dp = dict.fromkeys(p,"222")
print(dp)
print(c)
dfk = {}.fromkeys(c)
print(dfk)
dfkk = {}.fromkeys(c).keys()
print(list(dfkk))
dfkk
集合 Set¶
- 集合中每个元素都是无序的、不重复的任意对象
- 集合内数据无序,即无法使用索引和分片
- 集合内部数据元素具有唯一性,可以用来排除重复数据
集合定义¶
# 集合的定义: set()
s = set()
print(type(s))
print(s)
# 大括号内一定要有值,否则定义出的将是一个dict
s = {1,2,3,4,5,6,7}
print(s)
集合创建与运算¶
- 用list作为输入集合
- add()方法增加元素
- remove()方法删除元素
s = set([1,2,3])
s.add(6)
s.remove(2)
s
# 集合运算
s = {33,1,33,6,9,126,8,6,3,77,88,99,126}
print(s)
s = {33,1,33,6,9,126,8,6,3,77,88,99,126}
ss = {i for i in s}
print(ss)
s = {33,1,33,6,9,126,8,6,3,77,88,99,126}
sss = {i for i in s if i % 2 ==0}
print(sss)
s1 = {1,2,3,4}
s2 = {"I","love","you"}
s = {m*n for m in s2 for n in s1}
print(s)
print(len(s))
集合函数¶
- intersection:交集
- difference:差集
- union:并集
- issubset:检查一个集合是否为另一个子集
- issuperset:检查一个集合是否为另一个超集
s1 = {1,2,3,4,5,6,7}
s2 = {5,6,7,8,9}
#交集
s_1 = s1.intersection(s2)
print("交集:",s_1)
#差集
s_2 = s1.difference(s2)
print("差集:",s_2)
#并集
s_3 = s1.union(s2)
print("并集:",s_3)
#检查一个集合是否为另一个子集
s_4 = s1.issubset(s2)
print("检查子集结果:",s_4)
#检查一个集合是否为另一个超集
s_5 = s1.issuperset(s2)
print("检查超集结果:",s_5)
集合去重¶
# 嵌套式生成列表
#生成一个列表a
a = [i for i in range(1,4)]
print(a)
#生成一个列表b
b = [i for i in range(100,400) if i % 100 == 0]
print(b)
# 嵌套式
c = [m*n for m in a for n in b]
print(c)
list(set(c))
数据导入¶
csv格式数据导入
import pandas as pd
w=pd.read.csv("数据地址")
w.describe()
w.sort_values(by="列名")txt文件数据导入
- sep:分隔的正则表达式
x = pd.read_table('data4.txt', sep='\s+')
- sep:分隔的正则表达式
excel格式数据导入
import pandas as pd
pd.read_excel("数据地址")MySQL数据导入
import pandas as pd
import pymysql
dbconn=pymsql.connect(host="127.0.0.1",user="root",passwd="root",db="hexun")
sql="select * from myhexun"
w=pd.read_sql(sql,conn)
w.describe()
$JSON$¶
- JSON:JavaScript 对象表示法(JavaScript Object Notation)。
- JSON 是存储和交换文本信息的语法。类似 XML。
- JSON 比 XML 更小、更快,更易解析。
dumps 将一个字典转换成 json
dump 将一个文件转换成json
loads 读取sring 转化成字典
load 读取filename转化成字典
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串(用于写入文件) |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象(用于循环处理) |
json.dumps:字符串写入¶
#!/usr/bin/python
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data2 = json.dumps(data)
print(data2[0:5])
data2
#!/usr/bin/python
import json
data = [ {
"employees": [
{ "firstName":"Bill" , "lastName":"Gates" },
{ "firstName":"George" , "lastName":"Bush" },
{ "firstName":"Thomas" , "lastName":"Carter" }
]
} ]
# 使用参数让 JSON 数据格式化输出:
# 文件里只能写字符串,把json转成字符串,以便写入文件
data2 = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))
print(data2,'\n')
print('-'*20)
print(data2[0:15],'\n')
print('-'*20)
data2
json.loads:格式化输出¶
#!/usr/bin/python
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
print(type(text))
text['a']
text2 = '{"employees": [{ "firstName":"Bill" , "lastName":"Gates" },{ "firstName":"George" , "lastName":"Bush" },{ "firstName":"Thomas" , "lastName":"Carter" }]} '
data3= json.loads(text2)
data3
print(type(data3))
# 打印字典的所有key和values
print(data3.keys())
print(data3.values())
print(type(data3['employees'][0]))
print(data3['employees'][0].keys())
data3['employees'][0]['firstName']
循环读取keys和values¶
for i in range(len(data3['employees'][0])+1):
print(data3['employees'][i]['firstName'],'-',data3['employees'][i]['lastName'])
写入文件、读取文件¶
with open(r'sample.json','w+') as f:
# 打开一个新的 json文件,然后读写
f.write(data2)
with open('sample.json','r') as f:
reads=json.load(f)
print(type(reads))
print('-'*100)
print(reads)
print('-'*100)
print(type(reads[0]))
print('-'*100)
reads[0]
DateBase¶
- 非关系型数据库 Mongodb
- 关系型数据库 Postgresql
Mongodb¶
- 以键值的形似存储
- 与JSON相似
python连接¶
import pymongo
myclient=pymongo.MongoClient("mongodb://user:password@127.0.0.1/")
sample_db = myclient['demo-mongodb']
sample_hlinks=sample_db['demo-collections']
python操作¶
%run mongodb.py
sample(2)
Postgresql¶
python数据库连接¶
- conn='postgresql://user:password@127.0.0.1/demodb'
python数据库操作¶
%run postgresql.py
sql = "SELECT * FROM sku_list_full_copy where storename <> '晴天小店' limit 2;"
a = exe_sql(sql)
print(a)
Excel¶
- xlrd:对xls、xlsx、xlsm文件进行读操作–读操作效率较高,推荐
- xlwt:对xls文件进行写操作–写操作效率较高,但是不能执行xlsx文件
- openpyxl:对xlsx、xlsm文件进行读、写操作–xlsx写操作推荐使用
- 数据分析,直接使用DataFrame
xlrd¶
import xlrd
excel=xlrd.open_workbook('test.xlsx')
table = excel.sheet_by_name('Sheet1')
openpyxl¶
from openpyxl import load_workbook
excel=load_workbook('test.xlsx')
table = excel.get_sheet_by_name('Sheet1')
Pandas-DataFrame¶
- 1、读取Excel文件内容,经过简单清洗后,写入数据库
- 2、在数据库中进行ERL、DW开发,生成二维表Report
- 3、Python直接读取二维表Report用于可视化开发
dfa = pd.DataFrame(pd.read_excel('sample.xlsx', sheet_name='a'))
print(type(dfa))
dfa
dfb = pd.DataFrame(pd.read_excel('sample.xlsx', sheet_name='b'))
print(type(dfb))
dfb
数据导出¶
DataFrame.to_csv()
DataFrame.to_excel()
DataFrame.to_sql()
- 打开一个文件
f = open("sample.txt", "w") f.write( "I love Python 数据分析!\n" )
- 关闭打开的文件
f.close()
敬请期待《Python数据分析与数据挖掘-中篇》
